[Maximum number: 3]
This question explores how graph algorithms can be applied to a graph with an unknown edge weight.
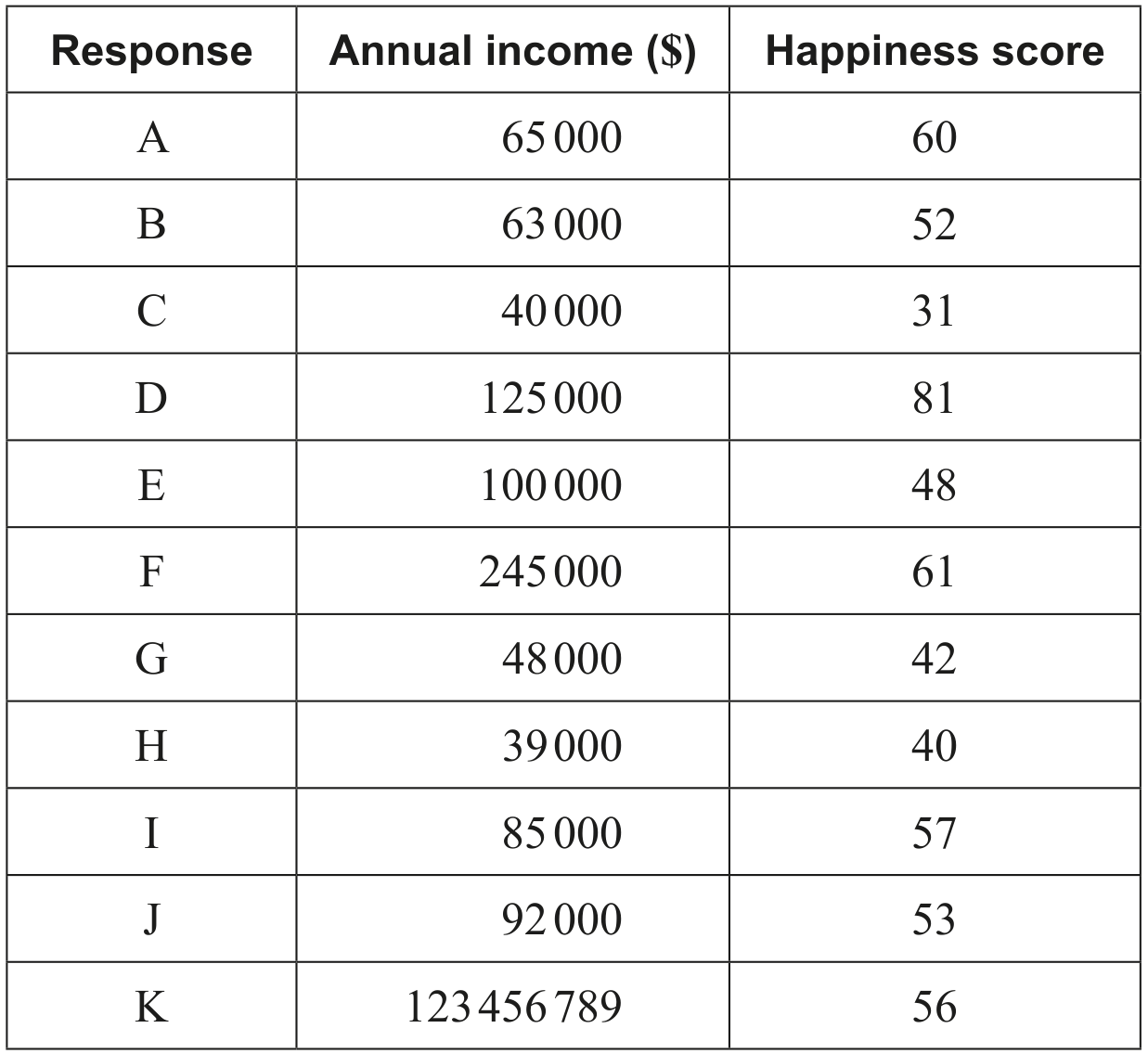
Graph W is shown in the following diagram. The vertices of W represent tourist attractions in a city. The weight of each edge represents the travel time, to the nearest minute, between two attractions. The route between A and F is currently being resurfaced and this has led to a variable travel time. For this reason, AF has an unknown travel time x minutes, where .
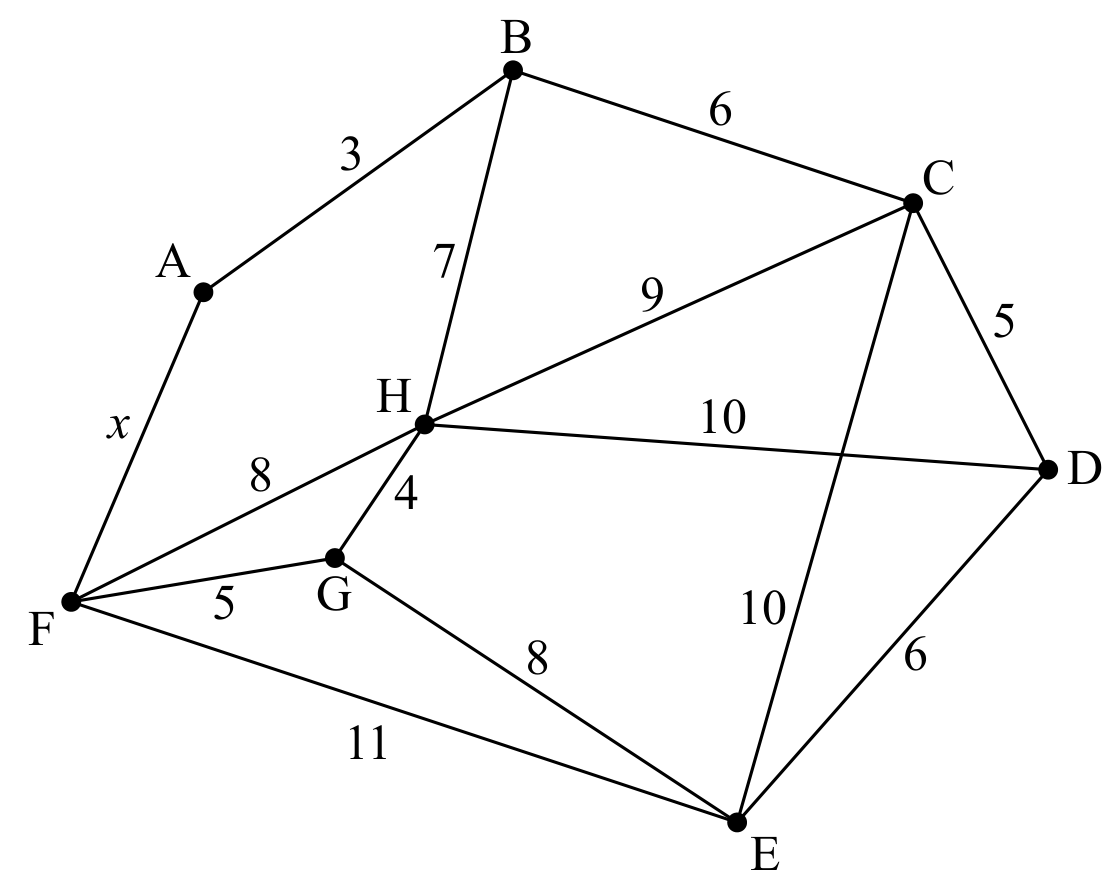
(a)
Write down the value of
[ 3 ]
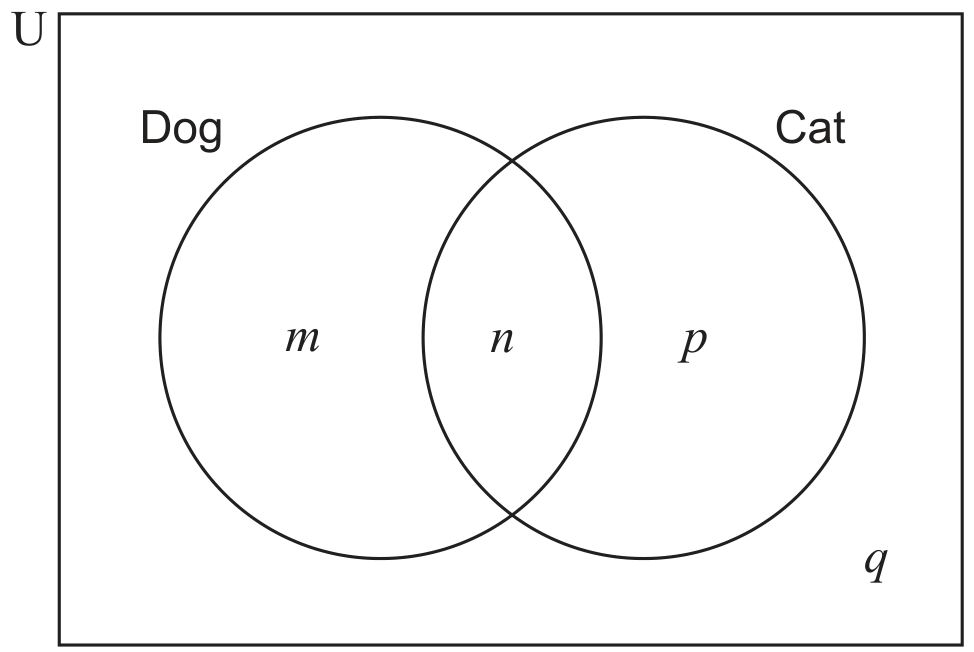
(i)
p;
[ 1 ]
(ii)
q;
[ 1 ]
(iii)
r.
To find an upper bound for Daniel's travel time, the nearest neighbour algorithm is used, starting at vertex A.
[ 1 ]